If a borderless world is an impossible fantasy, reducing borders between languages at least is not out of reach. With over 6,500 spoken languages around the globe, creating a unique customer service experience for everyone is a challenge faced by many companies around the world. The majority of existing applications in machine learning are language-specific which makes them not up to the challenge, as extending them to new languages implies the overhead of training from scratch. The future of many natural language understanding tasks lies in their ability to bridge the gap between different languages. But, how can this be made possible efficiently? No, you don’t even need a translator. The key is multilingual embeddings which open up countless opportunities for developing language agnostic models.
Multilingual Word Embeddings
Word embeddings are the mechanism that enables the representation of words in a low dimensional vector space. This ability makes it intuitive to work with words and deduce their relationships, as words that are similar in meaning are projected close to each other in the vector space. A natural extension which maps different languages to one common space is what we refer to as multilingual embeddings. Methodologies for devising such embeddings depend on the granularity of the alignment information: word, sentence, documents or their combination and on whether they are trained from scratch or fine-tuned on top of monolingual embeddings.
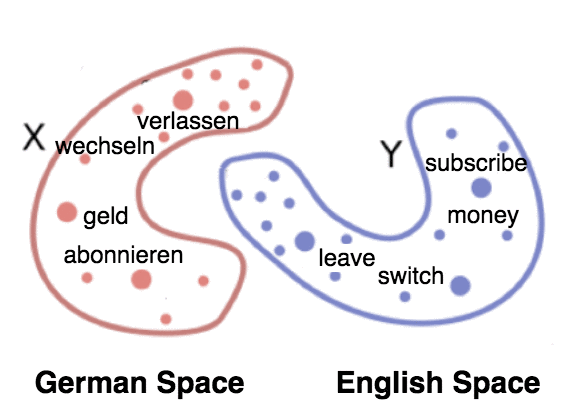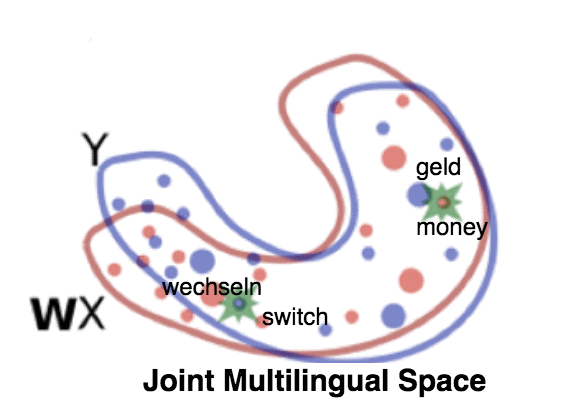
Evaluation of Multilingual Embeddings
The strategies used for evaluating this kind of embeddings fall into two categories: intrinsic and extrinsic. Intrinsic evaluation focuses on directly testing the ability of those embeddings in capturing syntactic and semantic relationships between words in tasks like cross-lingual nearest neighbors and word translation. On the other hand, extrinsic evaluation indirectly examines their performance when used as input features for downstream semantic transfer tasks such as cross-lingual document classification, multilingual chatbot intent detection and so on. Existing benchmarks for extrinsic evaluation focus on the comparison between the different multilingual embeddings when used for training on one language and testing on a different language, while a comparison between the performance using multilingual and monolingual training modes is obviously lacking. One distinct advantage of multilingual over monolingual training is their efficiency, as it is time-consuming to train multiple language-specific models while one single multilingual model can be trained once and do the trick. But, is there any accuracy gain over monolingual models?
Determining the usefulness of those embeddings across different semantic understanding tasks in terms of the gain in accuracy of the multilingual model over language-specific models is the primary focus of this master thesis. Our motivation is that not all languages are equally good by their own for all semantic tasks. For some languages, there are plenty of training resources, while other languages are under-represented. One way to reduce the gap between languages is through the semantic transfer of annotation from rich to low resourced languages. Other interesting use cases are multinational manifestations, where multiple languages can be combined to detect any anomalies in customer behavior around the world. Accurate anomalies are more likely to be detected if a language-agnostic model is used.
In this work, we develop an end-to-end systemic benchmarking system which revisits the previous benchmark for cross-lingual document classification and tackles unexplored applications namely cross-lingual churn detection and event detection. Our aim is to reach clear conclusions regarding for which applications, type of multilingual embeddings and configuration is the gain more pronounced.
Multilingual Text Classification:
We treat cross-lingual document classification and churn detection as two instances of one general framework: text classification. We design different experiments leveraging deep learning with different feature extractors (CNN, GRU with Attention or both), aggregators and different levels of deepness. We pick a representative set of multilingual embeddings trained independently and feed them to our classification pipeline. In a second experiment, we multi-task learning the embeddings alongside with the application at hand. This is a multivariate analysis, as it investigates the transfer learning gain for different languages, multilingual embeddings and text architectures.
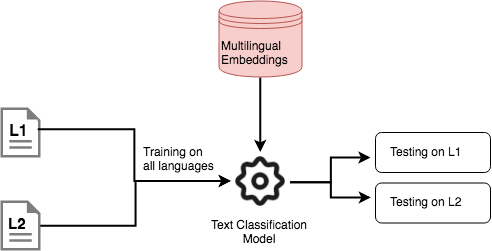
Multilingual Event Detection:
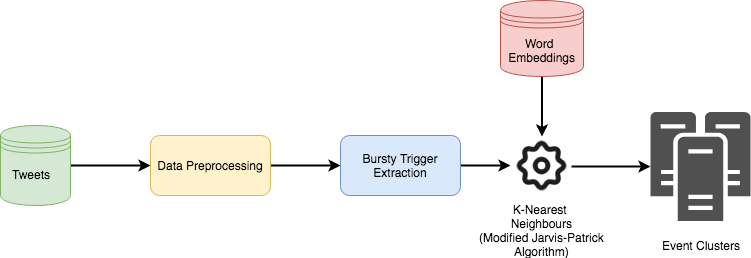
For event detection, we follow an unsupervised methodology based on the clustering of bursty keywords. We define an event as a cluster of semantically similar keywords which are not only important syntactically but also exhibit an unusual behavior with respect to the time distribution of tweets and number of users mentioning them. Word embeddings are harnessed to compute semantic similarities, then “Jarvis-Patrick Nearest Neighbours”, a scalable non-hierarchical clustering algorithm, is used. The generated clusters are evaluated against a set of sub-events in World Cup 2018.
Consistent Gain across Tasks !
We observe a consistent gain across different tasks especially for low resourced languages and less complex text classification architectures regardless of the type of the multilingual embeddings used. We observe a general tendency of multilingual embeddings fined-tuned on top of monolingual embeddings using techniques such as SVD, CCA to perform better for simpler text classification models.
For cross-lingual document classification, our results show that the gain in performance is at its best when a multilingual model is trained over the aggregation of all languages using a simple multi-layer perceptron achieving an average increase per language of 4.47%. The gain is of 7.66%, 6.63% and 3.2% for Italian, French and German respectively which matches the ascending order of language resourcefulness. We also achieve state-of-the-art performance on cross-lingual churn detection using a bidirectional GRU with attention implemented on top of CNN when training multilingually with F1-scores of 85.88% and 78.09% for English and German respectively which accounts for an cross-lingual average increase of 6.52%. In the same manner, we are able to prove the ability of the same model to generalize well to chatbot conversations.
As far as event detection is concerned, the gain in favor of the multilingual approach is well pronounced, as it not only detects more event clusters but also those events are rich in content as the number of tweets to which they are linked is higher. These clusters are also shown to be better correlated with real-world sub-events in world cup 2018 dataset, such as goals, penalties and so on.
I would like to express my special thanks to Christian Abbet and Athanasios Giannakopoulos for their collaboration on cross-lingual churn detection part. For more details in this regard, interested readers are invited to check this article Churn Intent Detection - Keep the fish in your bowl.
This project is conducted under the supervision of Dr. Claudiu Musat from Swisscom, Switzerland telecommunication leader, and the Swisscom Digital Lab, an innovation lab located in the EPFL Innovation Park dedicated to conduct applied research in machine learning, data analytics, security and communication systems. It is also in close collaboration with Prof. Robert West from Data Science Lab at EPFL.

Comments