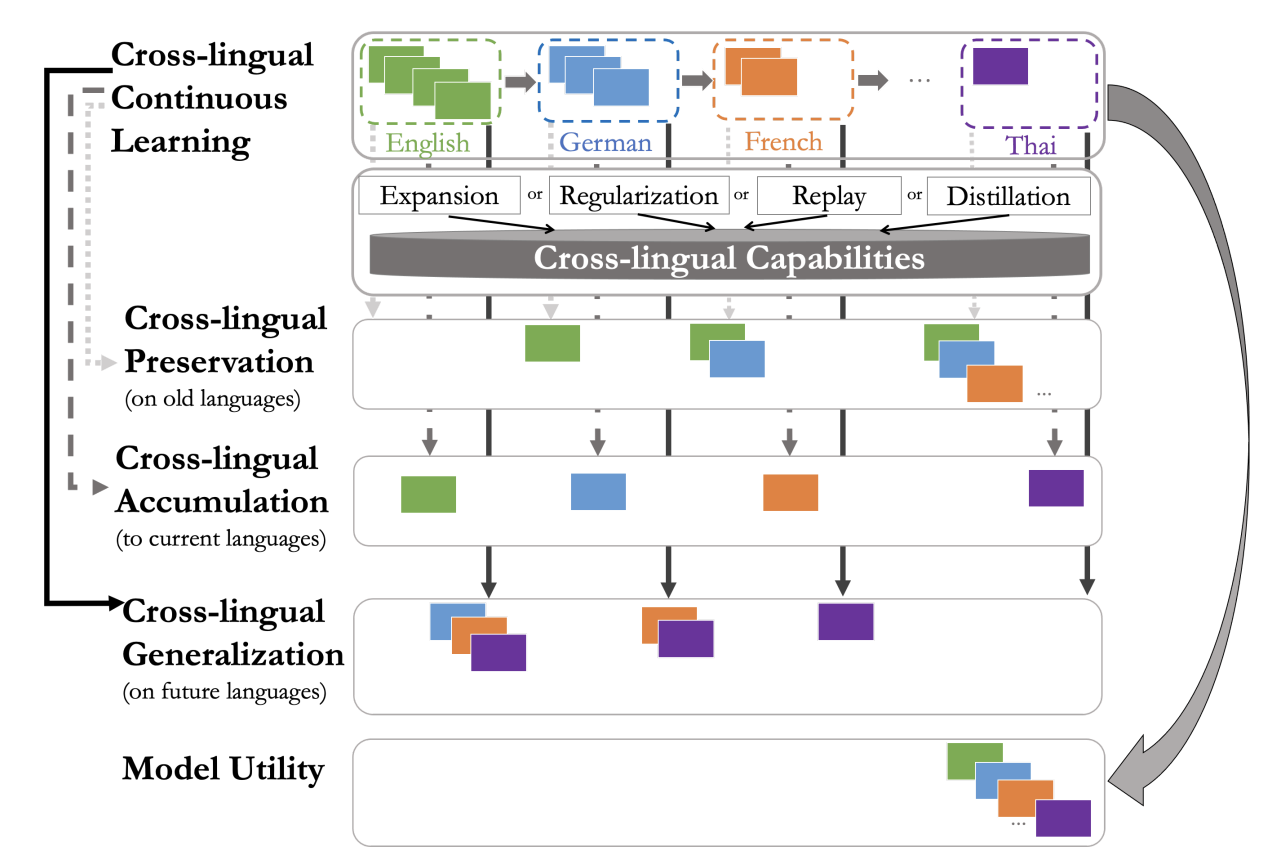
Cross-lingual Continual Learning:
Meryem M’hamdi, Xiang Ren, and Jonathan May (ACL’23)
The longstanding goal of multi-lingual learning has been to develop a universal cross-lingual model that can withstand the changes in multi-lingual data distributions. There has been a large amount of work to adapt such multi-lingual models to unseen target languages. However, the majority of work in this direction focuses on the standard two-hop transfer learning pipeline from source to target languages, whereas in realistic scenarios, new languages can be incorporated at any time in a sequential manner. In this paper, we present a principled \textbf{C}ross-lingual \textbf{C}ontinual \textbf{L}earning (CCL) evaluation paradigm, where we analyze different categories of approaches used to continually adapt to emerging data from different languages. We provide insights into what makes multilingual sequential learning particularly challenging. To surmount such challenges, we benchmark a representative set of cross-lingual continual learning algorithms and analyze their knowledge preservation, accumulation, and generalization capabilities compared to baselines on carefully curated datastreams. The implications of this analysis include a recipe for how to measure and balance different cross-lingual continual learning desiderata, which go beyond conventional transfer learning.
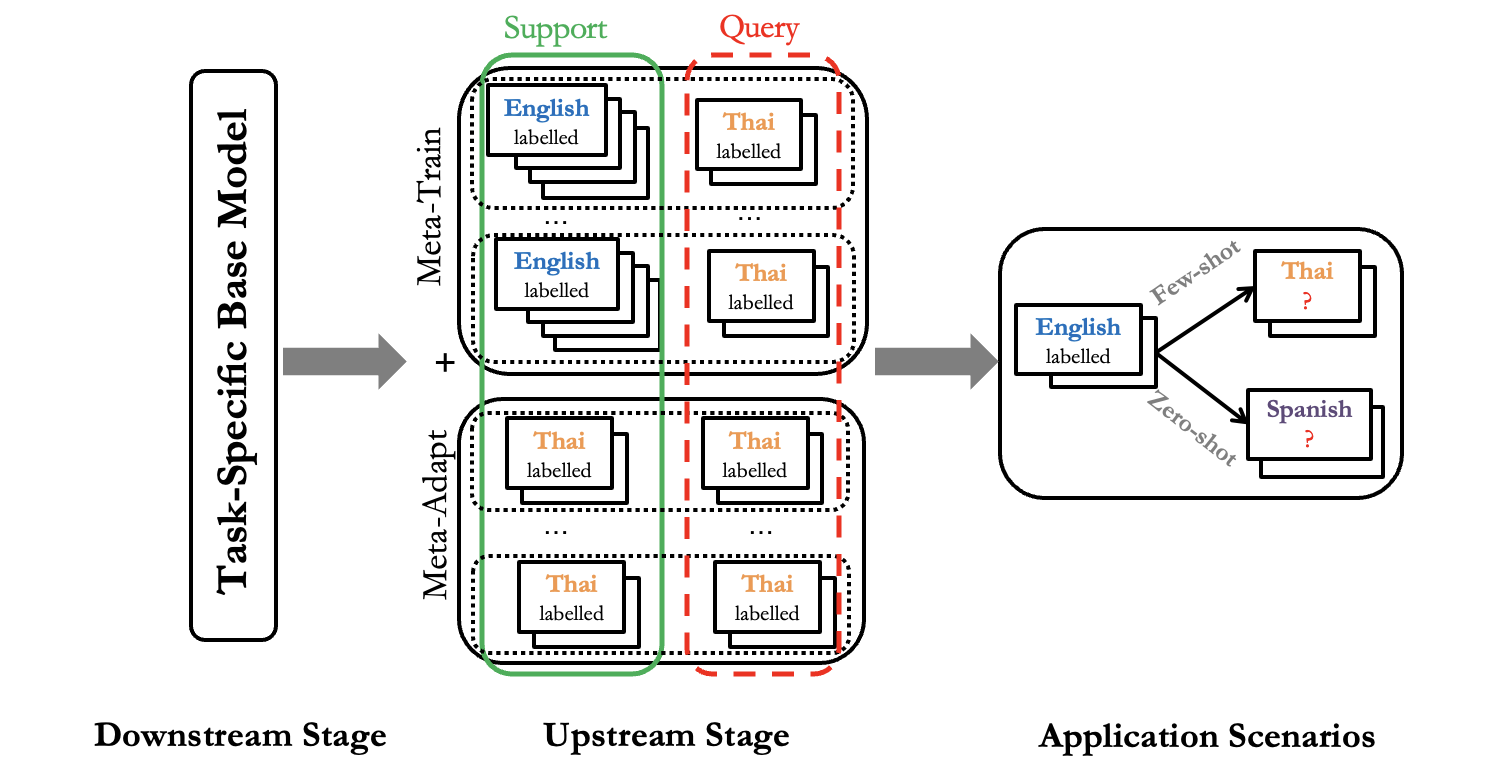
X-METRA-ADA: Cross-lingual Meta-Transfer learning Adaptation to Natural Language Understanding and Question Answering:
Meryem M’hamdi, Doo Soon Kim, Franck Dernoncourt, Trung Bui, Xiang Ren, Jonathan May (NAACL’21)
Multilingual models, such as M-BERT and XLM-R, have gained increasing popularity, due to their zero-shot cross-lingual transfer learning capabilities. However, their generalization ability is still inconsistent for typologically diverse languages and across different benchmarks. Recently, meta-learning has garnered attention as a promising technique for enhancing transfer learning under low-resource scenarios: particularly for cross-lingual transfer in Natural Language Understanding (NLU). In this work, we propose X-METRA-ADA, a cross-lingual MEta-TRAnsfer learning ADAptation approach for NLU. Our approach adapts MAML, an optimization-based meta-learning approach, to learn to adapt to new languages. We extensively evaluate our framework on two challenging cross-lingual NLU tasks: multilingual task-oriented dialog and typologically diverse question answering. We show that our approach outperforms naive fine-tuning, reaching competitive performance on both tasks for most languages. Our analysis reveals that X-METRA-ADA can leverage limited data for faster adaptation.
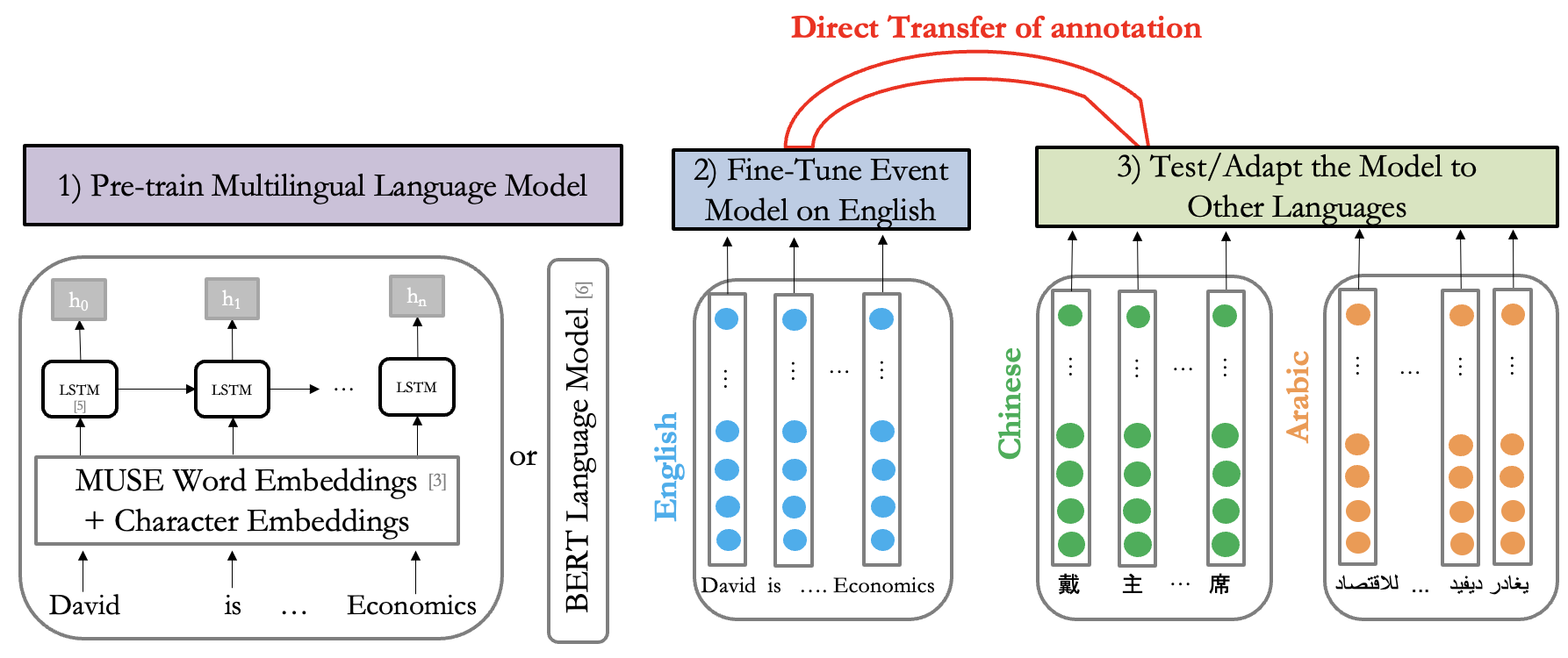
Contextualized cross-lingual event trigger extraction with minimal resources:
Meryem M’hamdi, Marjorie Freedman, Jonathan May (CoNLL’19)
Event trigger extraction is an information extraction task of practical utility, yet it is challenging due to the difficulty of disambiguating word sense meaning. Previous approaches rely extensively on hand-crafted language-specific features and are applied mainly to English for which annotated datasets and Natural Language Processing (NLP) tools are available. However, the availability of such resources varies from one language to another. Recently, contextualized Bidirectional Encoder Representations from Transformers (BERT) models have established state-of-the-art performance for a variety of NLP tasks. However, there has not been much effort in exploring language transfer using BERT for event extraction. In this work, we treat event trigger extraction as a sequence tagging problem and propose a cross-lingual framework for training it without any hand-crafted features. We experiment with different flavors of transfer learning from high-resourced to low-resourced languages and compare the performance of different multilingual embeddings for event trigger extraction. Our results show that training in a multilingual setting outperforms language-specific models for both English and Chinese. Our work is the first to experiment with two event architecture variants in a cross-lingual setting, to show the effectiveness of contextualized embeddings obtained using BERT, and to explore and analyze its performance on Arabic.
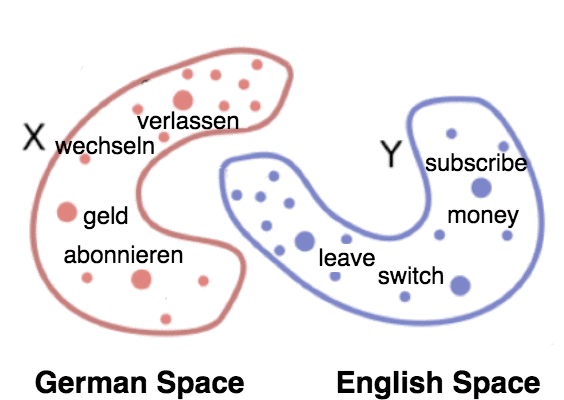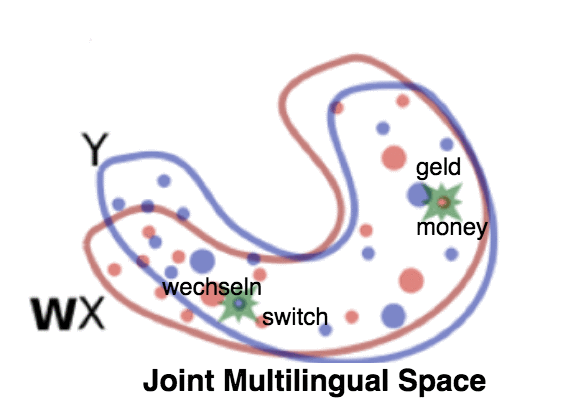
Creation and Evaluation of Multilingual Embeddings on Downstream Sematic Applications:
Christian Abbet, Meryem M’hamdi, Athanasios Giannakopoulos, Robert West, Andreea Hossmann, Michael Baeriswyl, Claudiu Musat (ConLL’18) Meryem M’hamdi, Robert West, Andreea Hossmann, Michael Baeriswyl, Claudiu Musat (ArXiv’19) *equal contribution
In this thesis, we start by reproducing some state-of-the-art methodologies for creating multilingual embeddings for four languages: English, German, French and Italian. We focus on fine-tuned models due to their efficiency and obtain some models already trained from scratch for comparison.
We directly integrate the learned embeddings into a pipeline of several downstream applications namely document classification and churn detection. We follow state-of-the-art methodology for each task leveraging deep learning models mainly a combination of CNN and GRU and hierarchical attention networks.
In a second experiment, we jointly train the embeddings and the document classification to test the impact of specializing the embeddings to the current task and deduce how well the embeddings can do by themselves. We define a new pipeline for performing unsupervised event detection which benefits from multilingual embeddings and different metrics for evaluating their performance and apply this approach to 11 different languages.
In all experiments, we compare the performance of multilingual training with multilingual embeddings to its monolingual counterpart.
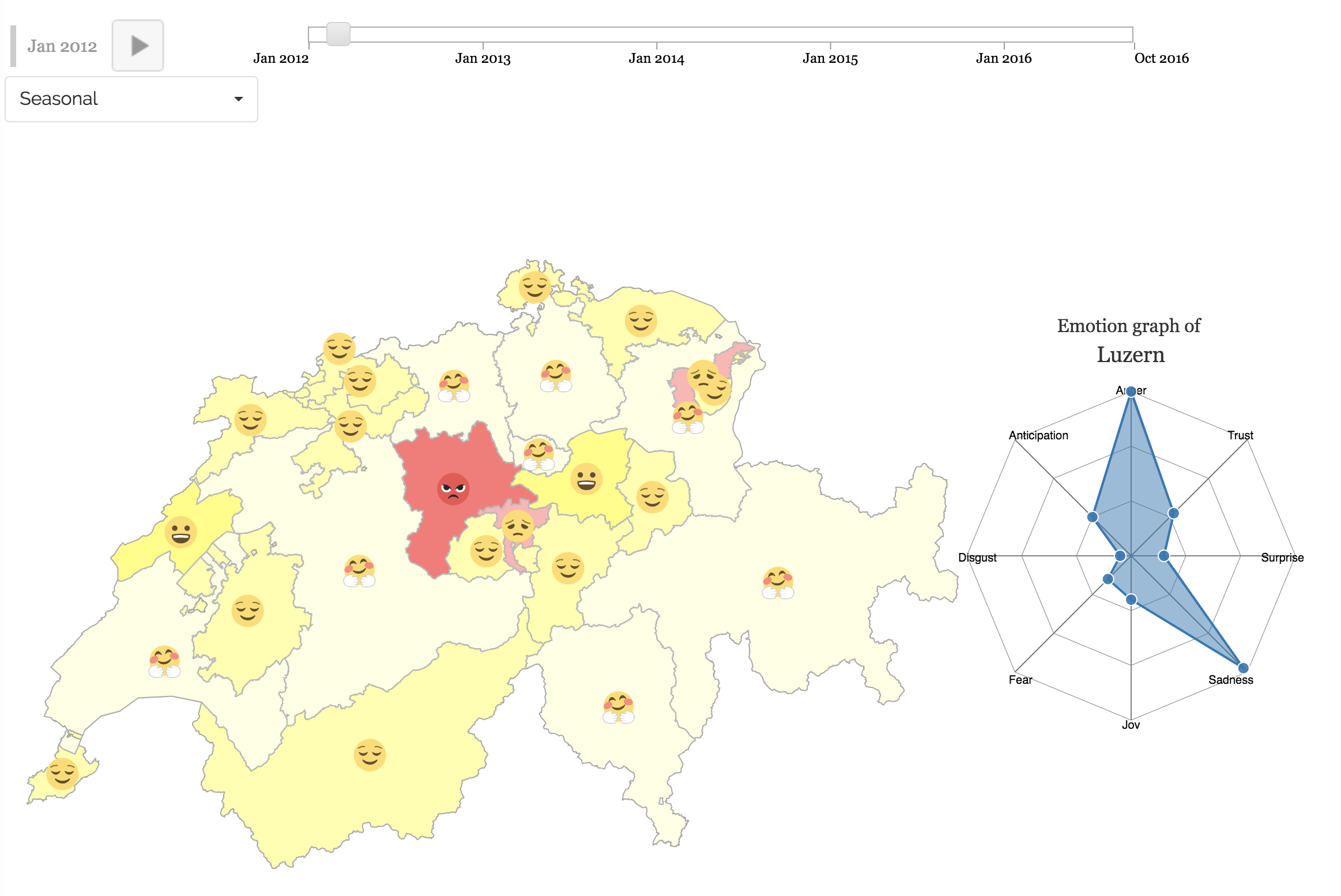
Estimation and Visualization of Canton-Level Moods using Hybrid Fine-Grained Emotion Analysis Methodologies:
Meryem M’hamdi, Gökçen Nurlu, and Riyadh Alnasser* *equal contribution
The goal of the project is to build a platform for capturing sentiments and emotions expressed using twitter in swiss cantons. The platform uses Twitter as a data source and combines sentiment analysis, Hybrid Fine-Grained Emotion Analysis Methodologies, and visualization techniques in order to provide users with an interactive interface for data exploration.
This platform provides interactive maps in order to give users the possibility to have a comprehensive overview of the sentiment and emotion analysis results about Swiss cantons and with the opportunity to zoom in to a specific canton to visualize the distribution of emotions and sentiment during a specific time.
The platform allows users to tune their view on such huge amount of information and to interactively reduce the inherent complexity, possibly providing a hint for finding meaningful patterns, and correlation between moods/emotion and time.
Fine Grained Emotion Recognition in Human Dialogs using Hybrid Methodologies:
Meryem M’hamdi, Valentina Sinstova, and Pearl Pu Emotions are the basis of human-human communication as they help us tune our understanding of the conversation and respond adequately. Lately there has been a surge to embed them in different human computer interaction applications including dialogue systems.
In this work, we follow a fine-grained hybrid approach to emotion detection applied to the context of human dialogues, which extends a lexicon-based approach with syntactic rules and semantic similarity analysis. We compare it to machine learning models trained on annotated dataset from another domain and to majority voting model between hybrid and transfer learning based. We describe the crowd-sourcing experiment designed to validate the accuracy of the emotion detection algorithms used. We show that hybrid rule-based approach extended with PMI semantic similarity improves the performance of our initial lexicon-based baseline. We then reflect on a model of emotional responses that shows the interactions between the emotions of the different actors in dialogue turns and that can be directly embedded in a response generation system.

Predicting grade improvement in problem submissions based on video and forum activities using MOOC data:
This work aims at predicting grade improvement in problem submissions based on certain patterns in video and forum activities in the course.
In this work, we dig deep into the analysis of the MOOC dataset, study correlations of different subsets of both existing, new and aggregated features with the grade difference, fit different machine learning classifiers and models and fine tune their parameters to increase their performance. We will present in what follows the rational used to extract and select a subset of features that when fed to different algorithms give us the best possible results.
We argue that Random Forest is the best algorithm in the case of classification as it gave us improved performance of 64% on the test dataset, while Gradient Boosting Machine algorithm gave the smallest error of 35.94% in the case of regression.